Construction kit for AI applications
Rework / New feature
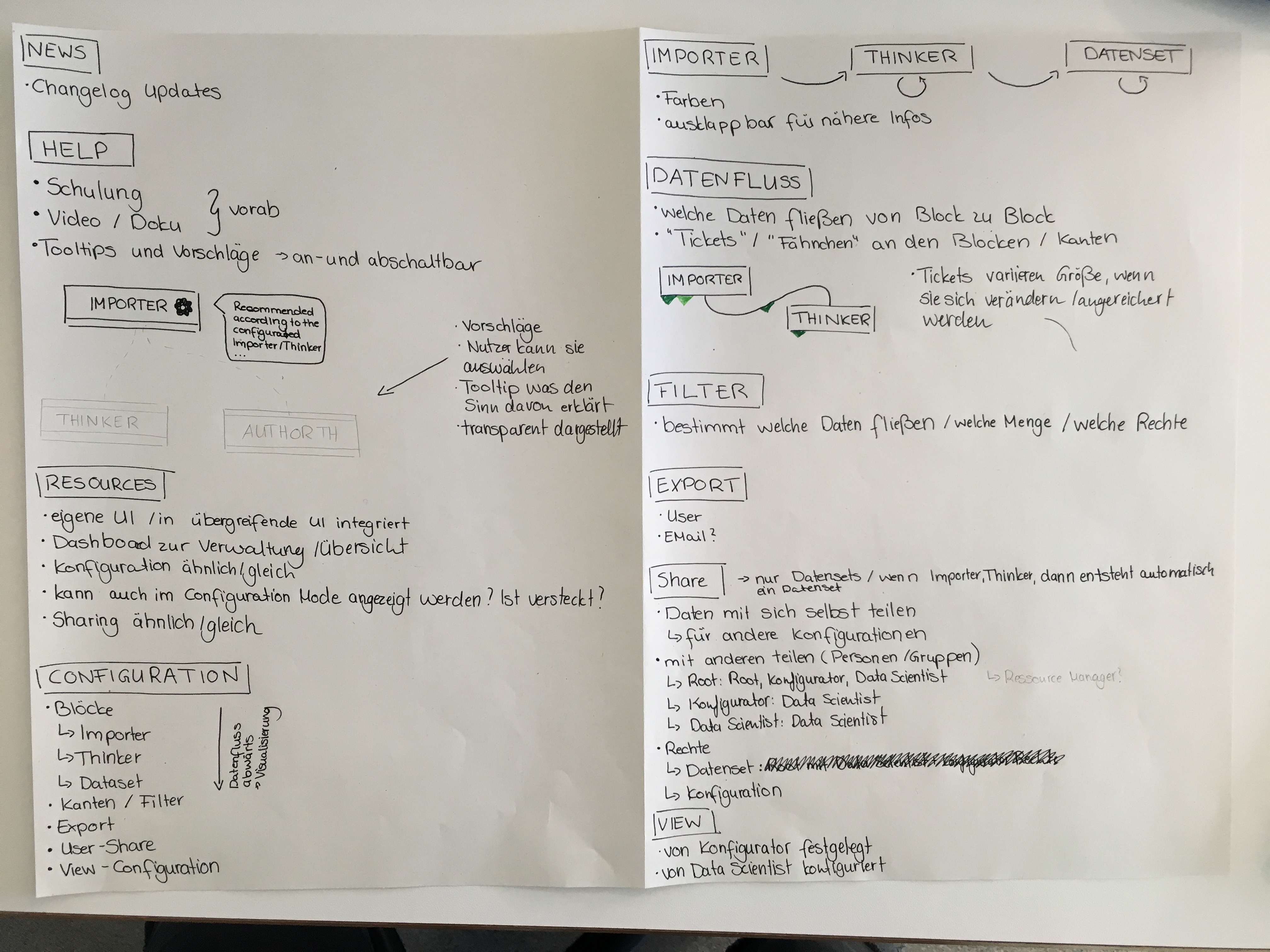
The project
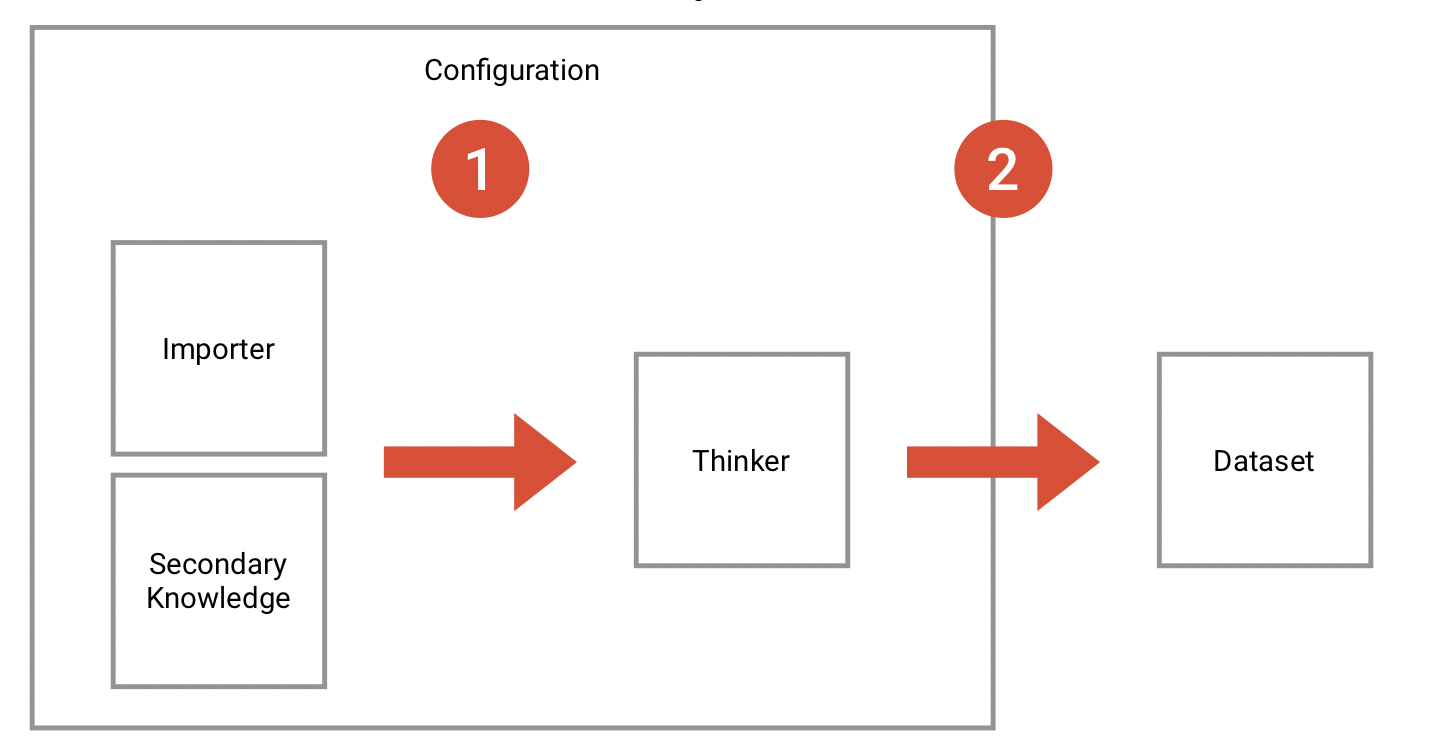
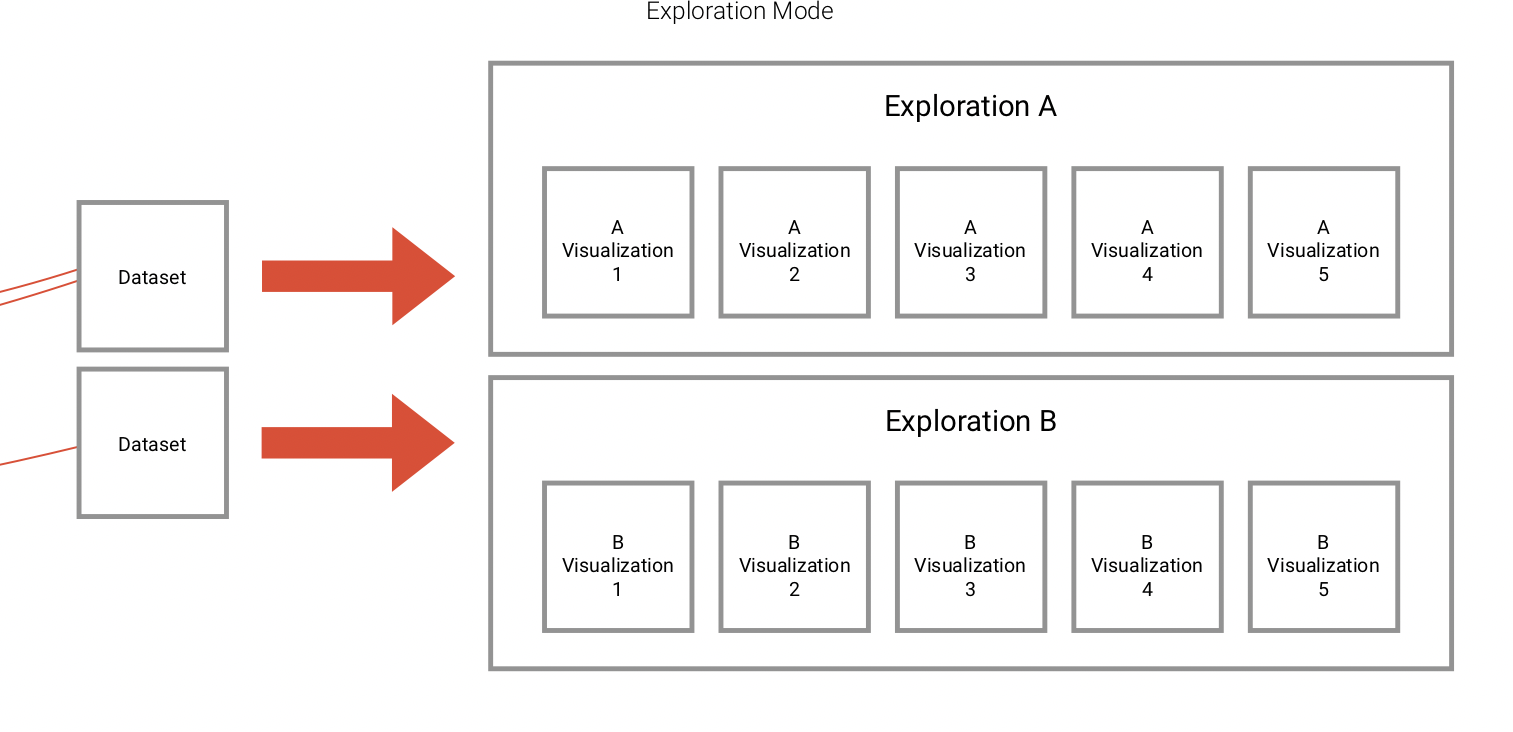
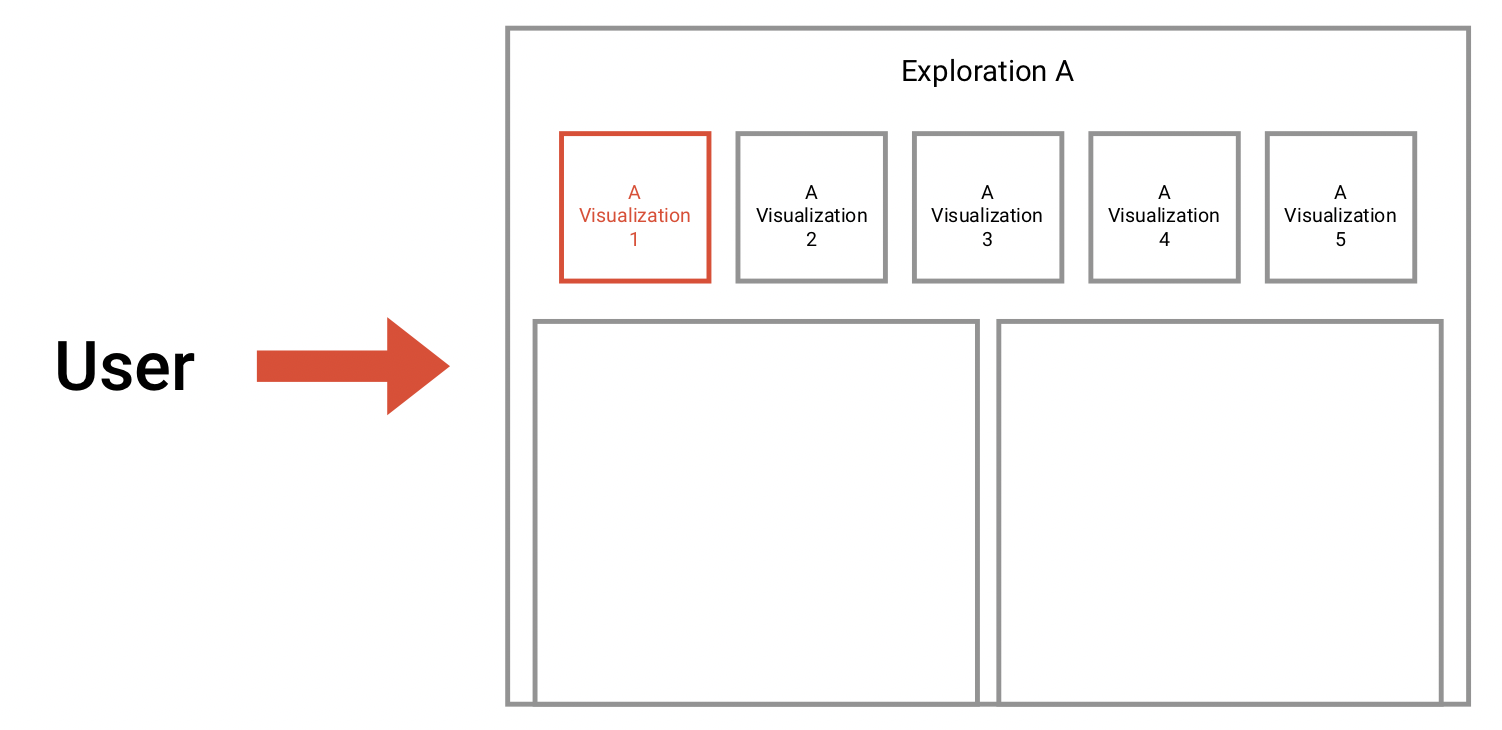
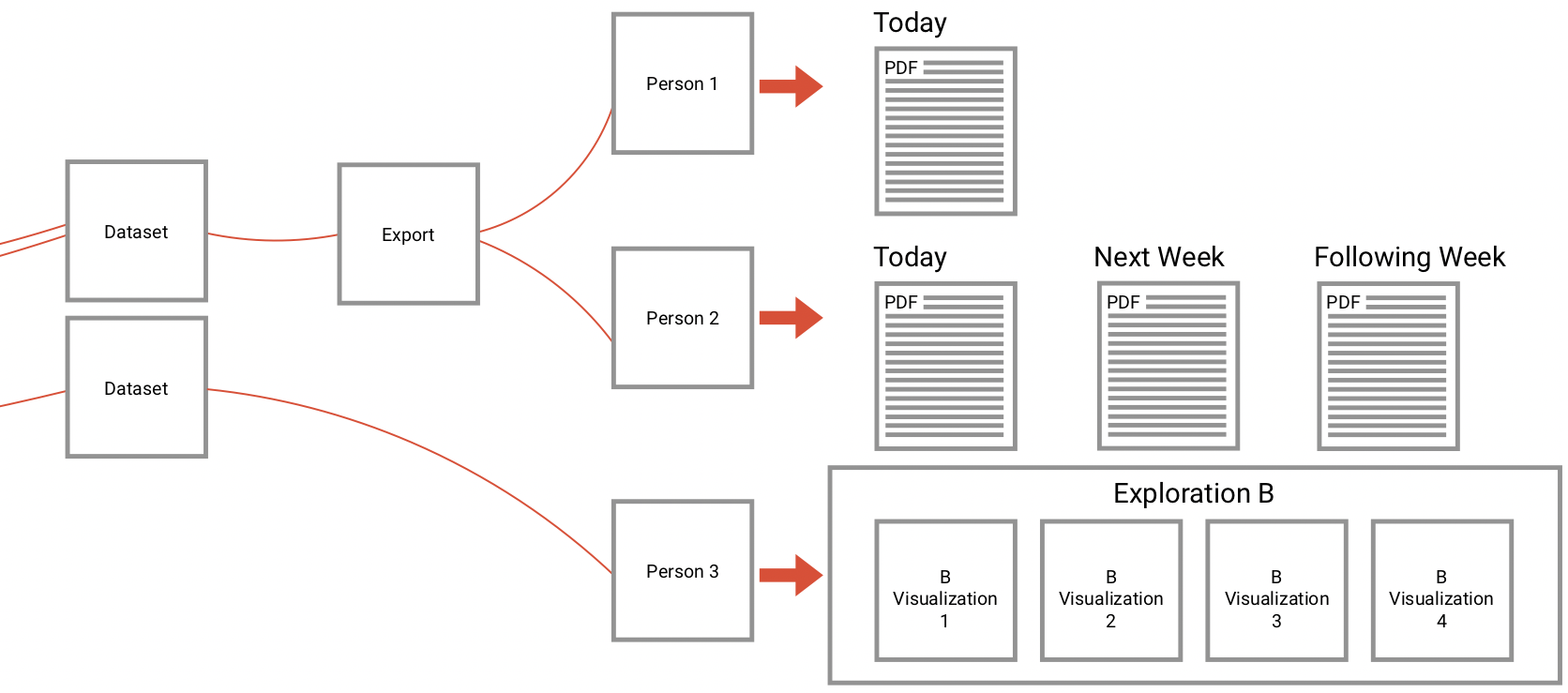
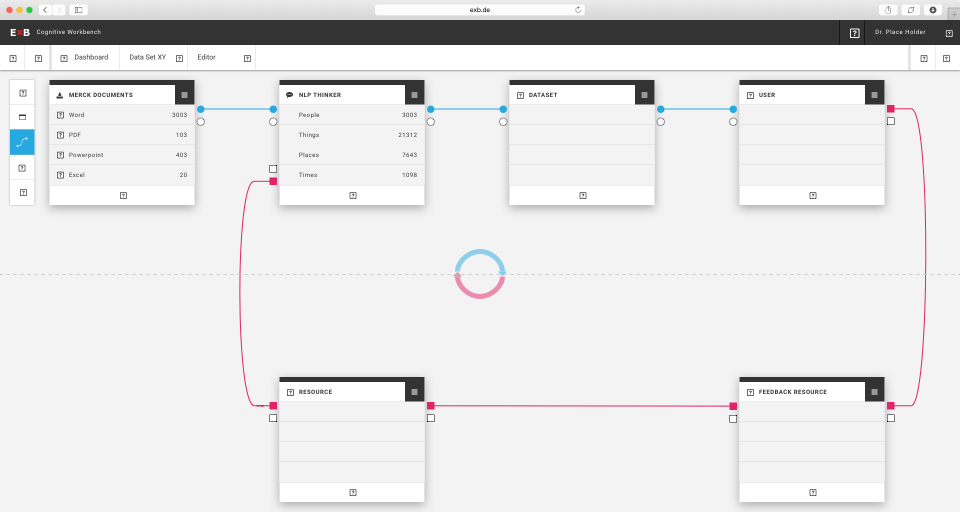
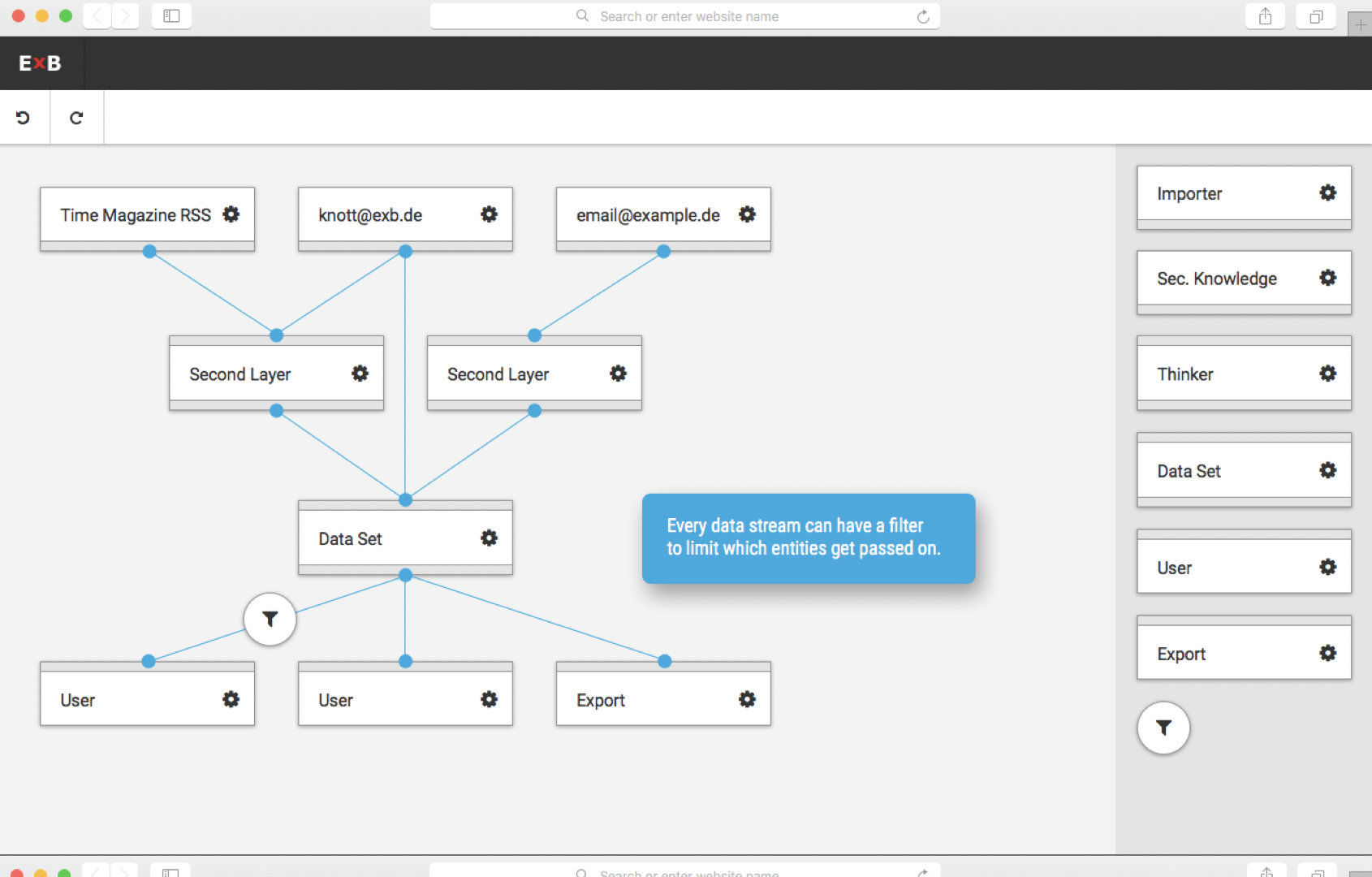
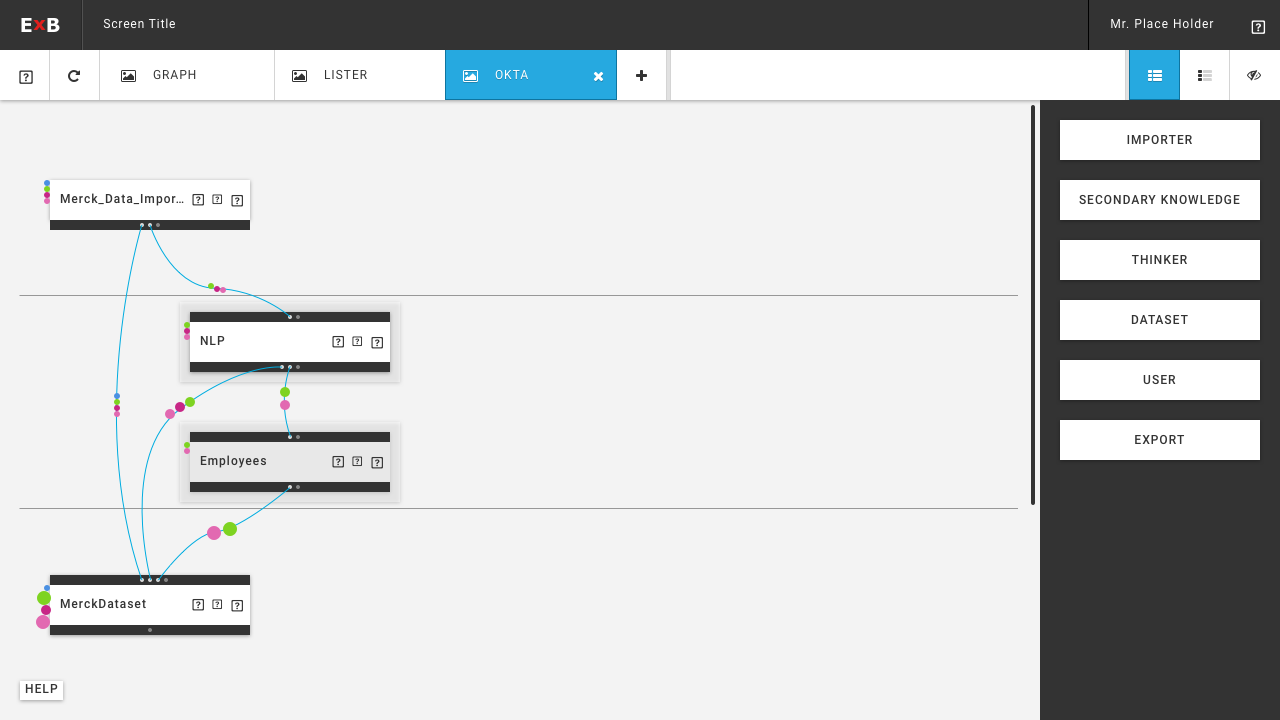
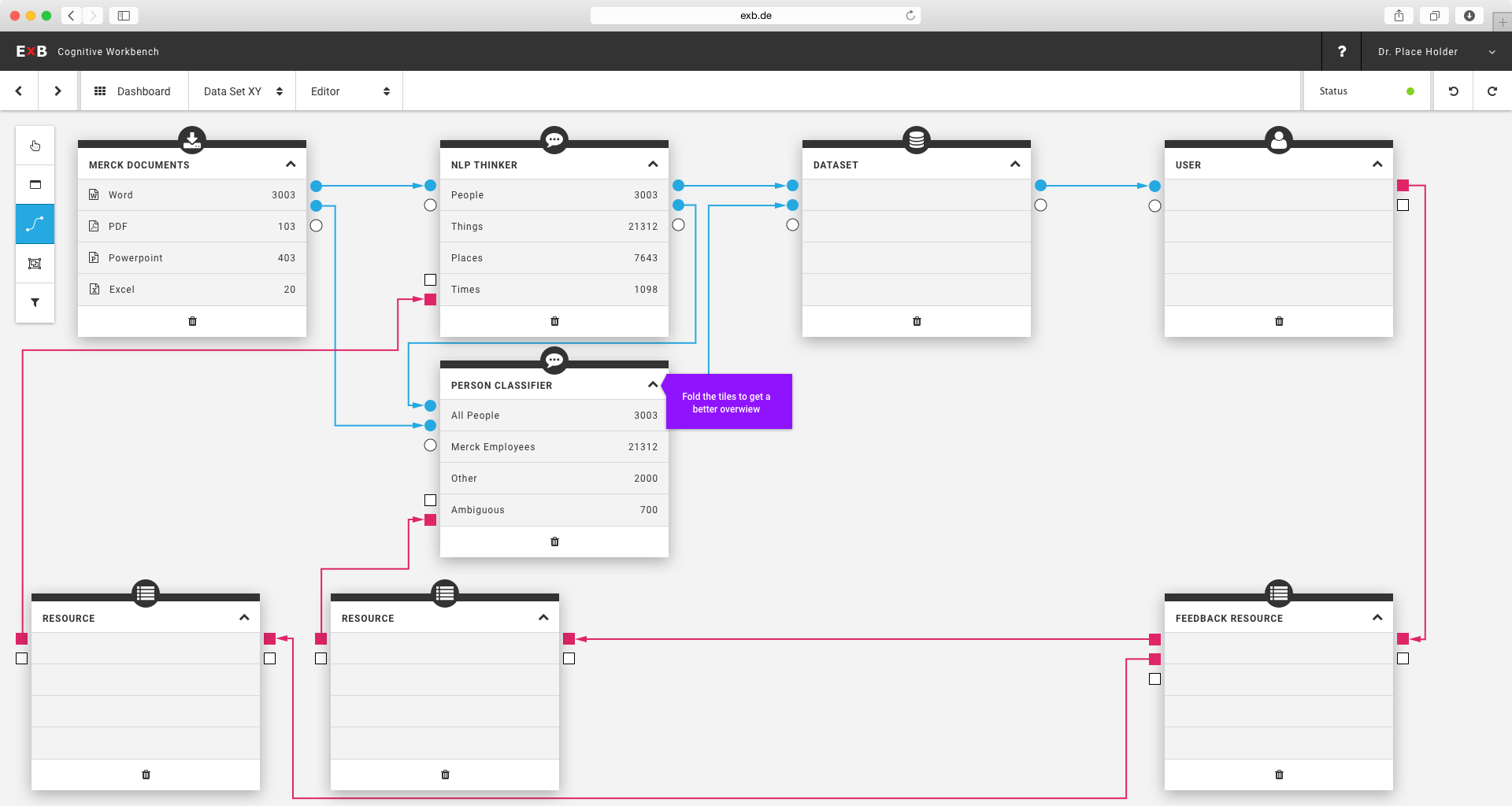
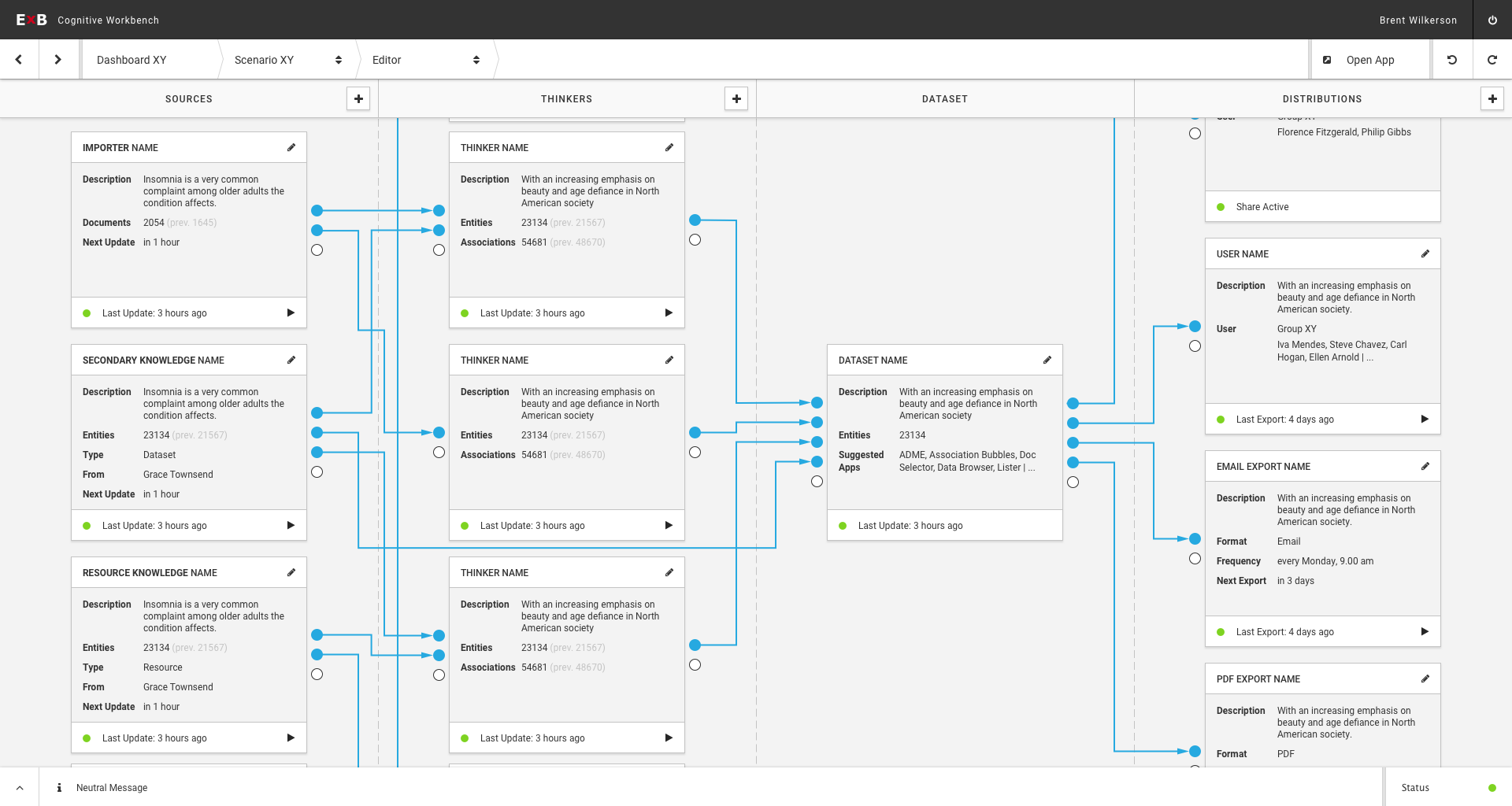
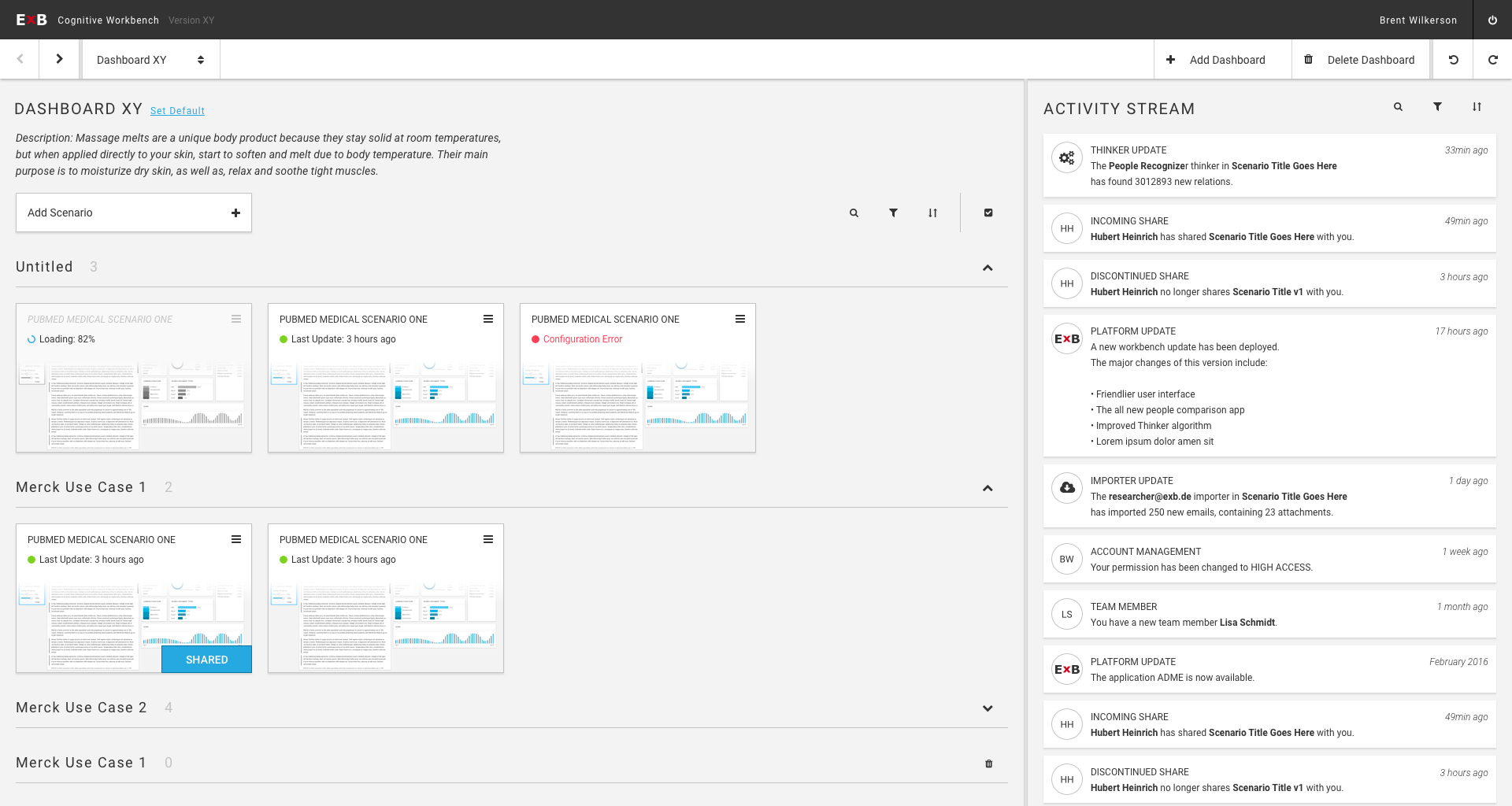
Since ExB's main product has developed extremely fast, it was time to make it customer-ready. The product is a generic NLP based machine learning / artificial intelligence platform called Cognitive Workbench (CWB). With it, ExB enables its customers organize, configure and modify cognitive computing applications to find new answers for difficult problems. The main benefits of this application is the computing power, the capability to capture large amounts of data and that it combining text, images, documents and structured data.
Until 2016, the CWB was an internal tool of the company. I was part of the ambitious project to redesign and prepare the platform for customer use. One challenge was that the system should continue to serve our research employees, and it was clear that it would evolve. At the same time, users without prior knowledge of artificial intelligence or machine learning should be able to use it.

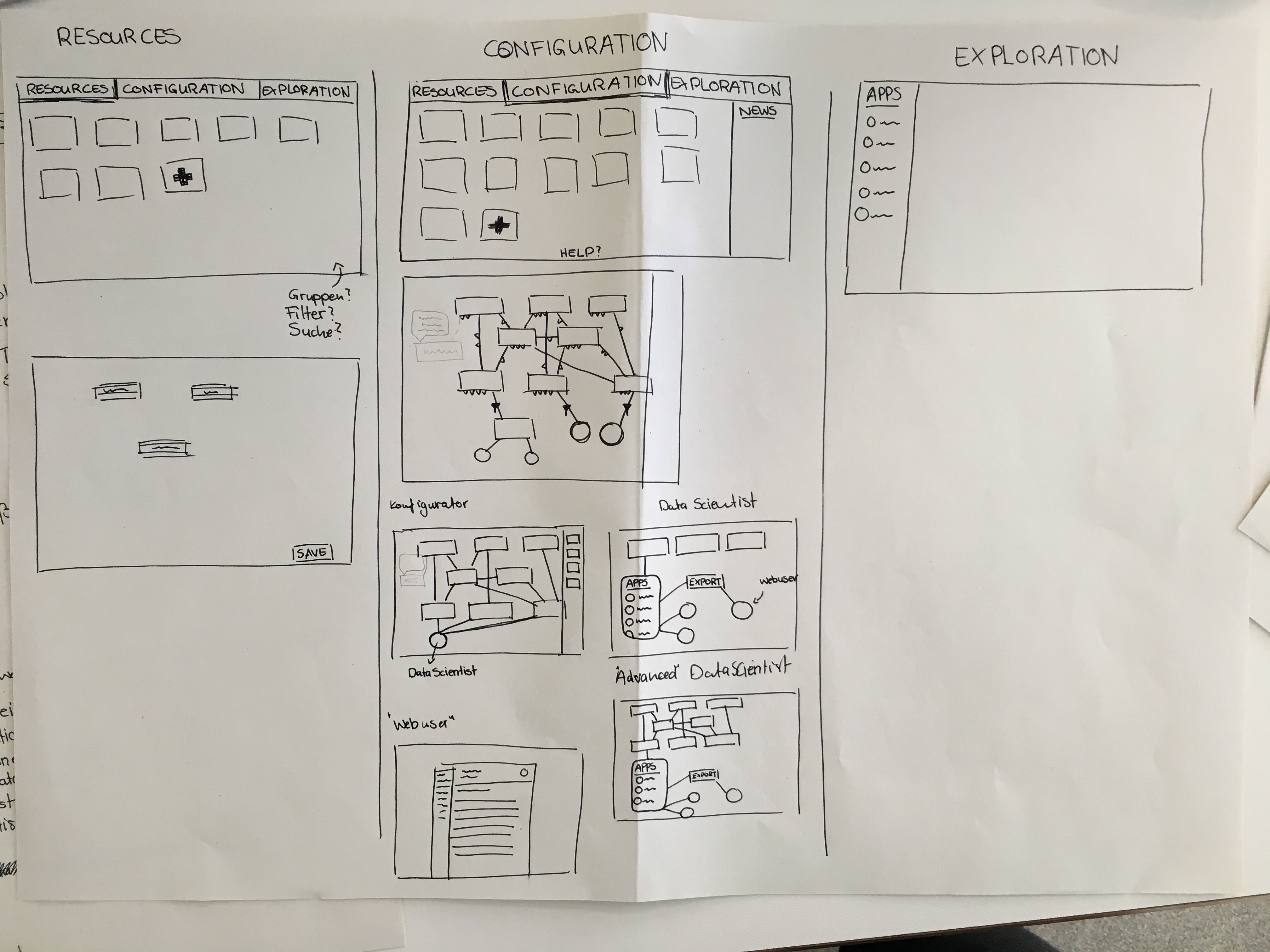
The Cognitive Workbench 1.0 - an internally used research and development tool