Automated Text Classification
New feature
This project was done during my time at ExB.

The project
ExB's Cognitive Workbench (CWB) was mainly used for entity and relation extraction in documents.
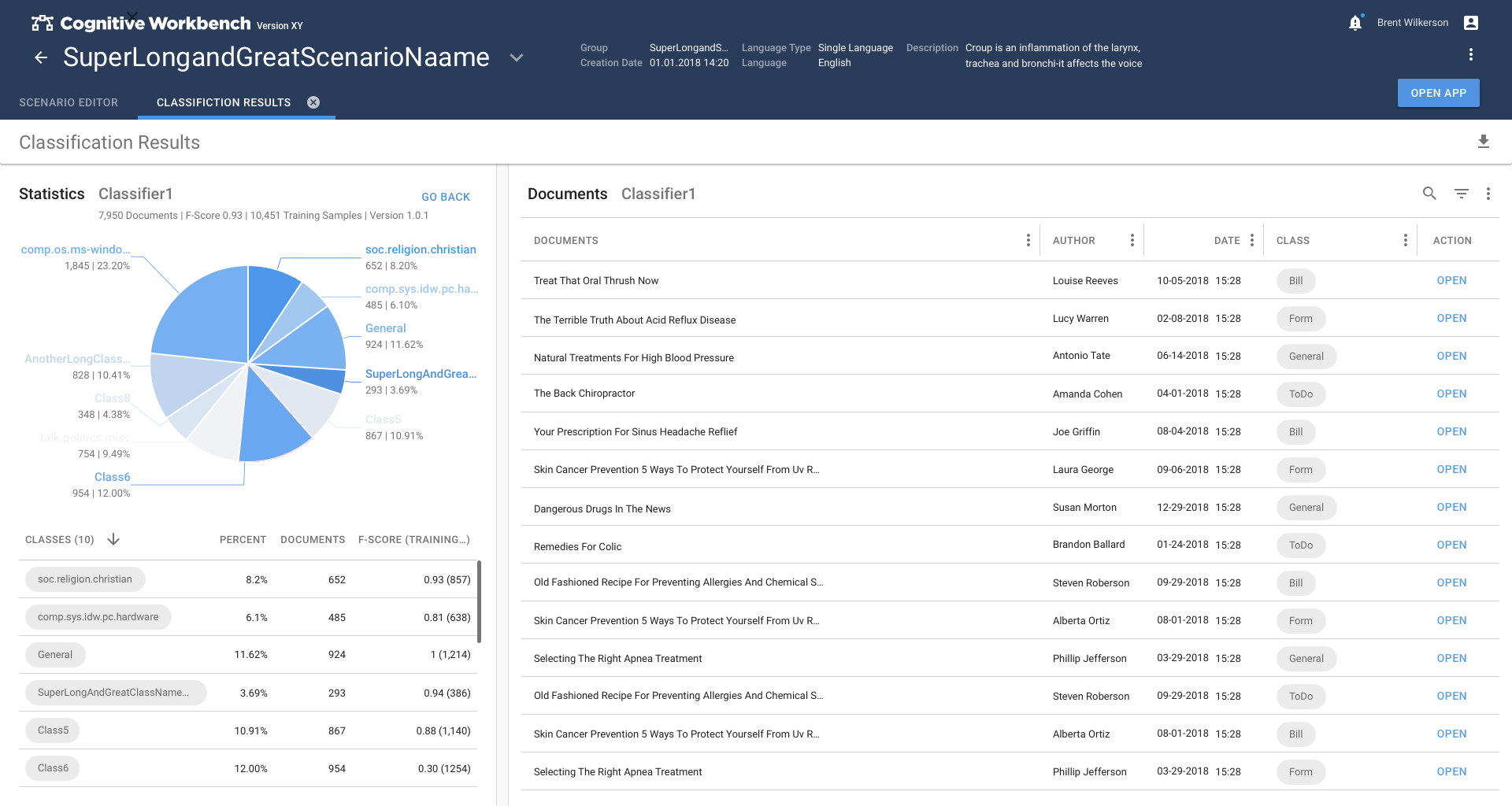
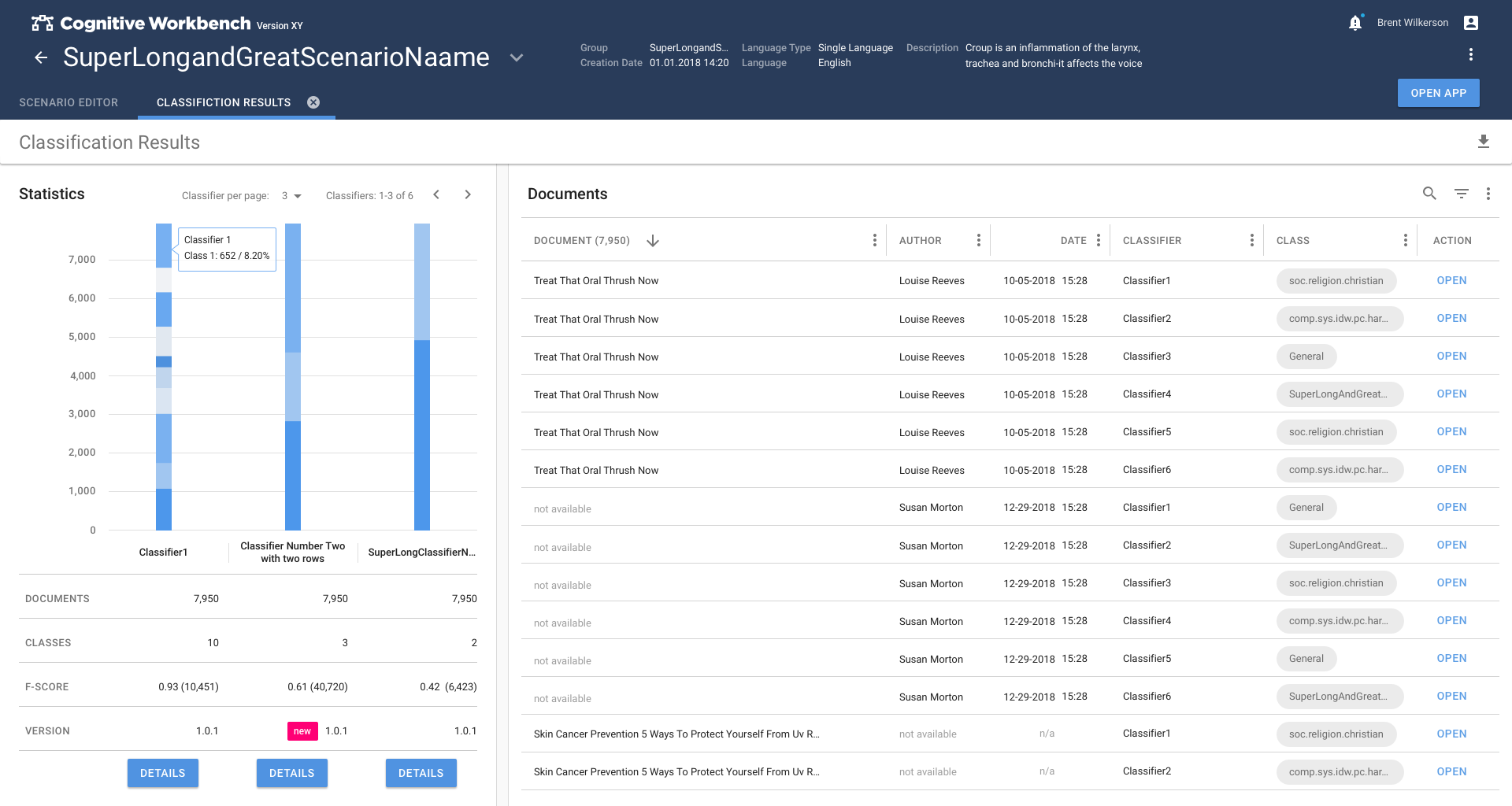
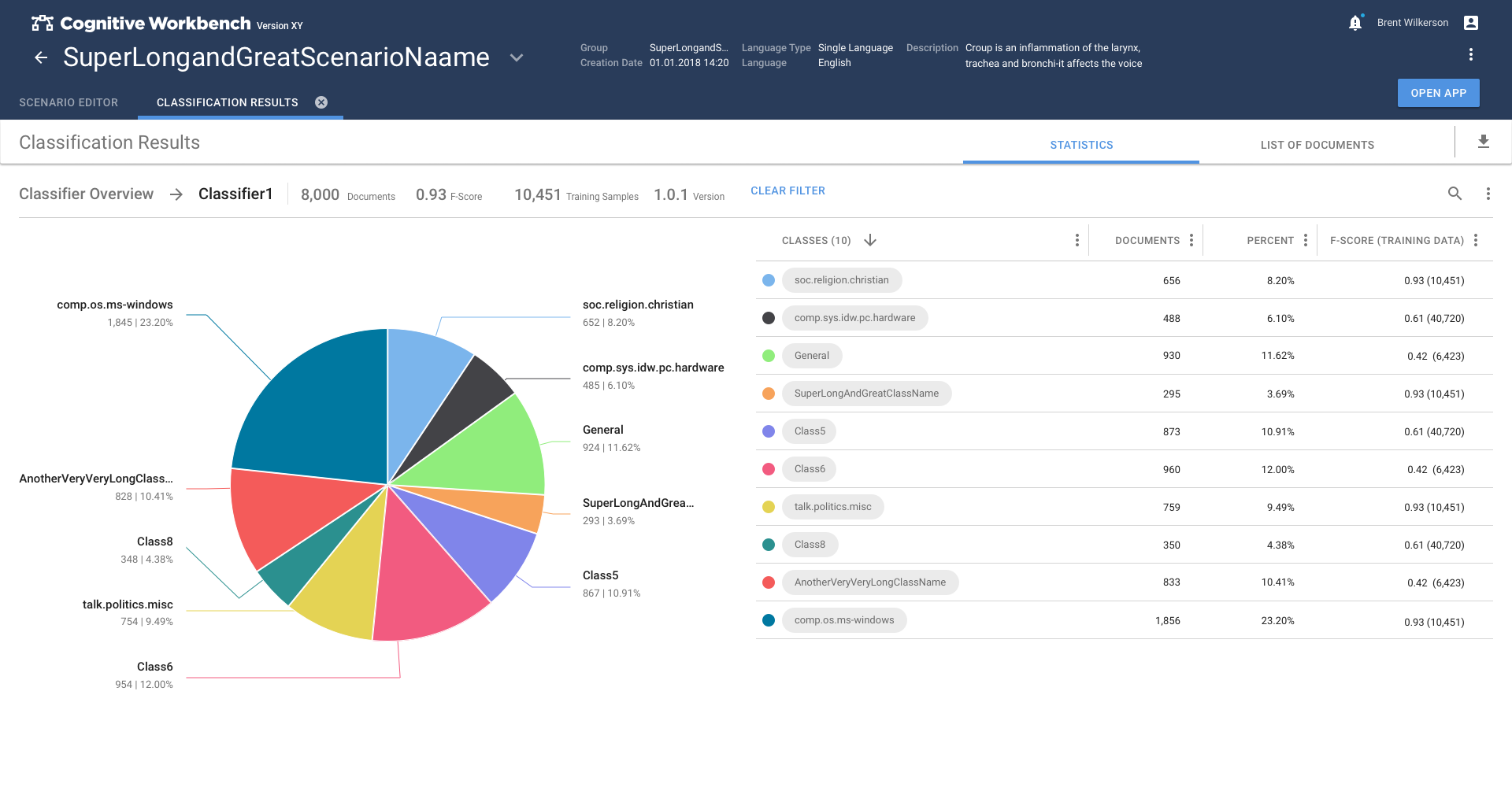
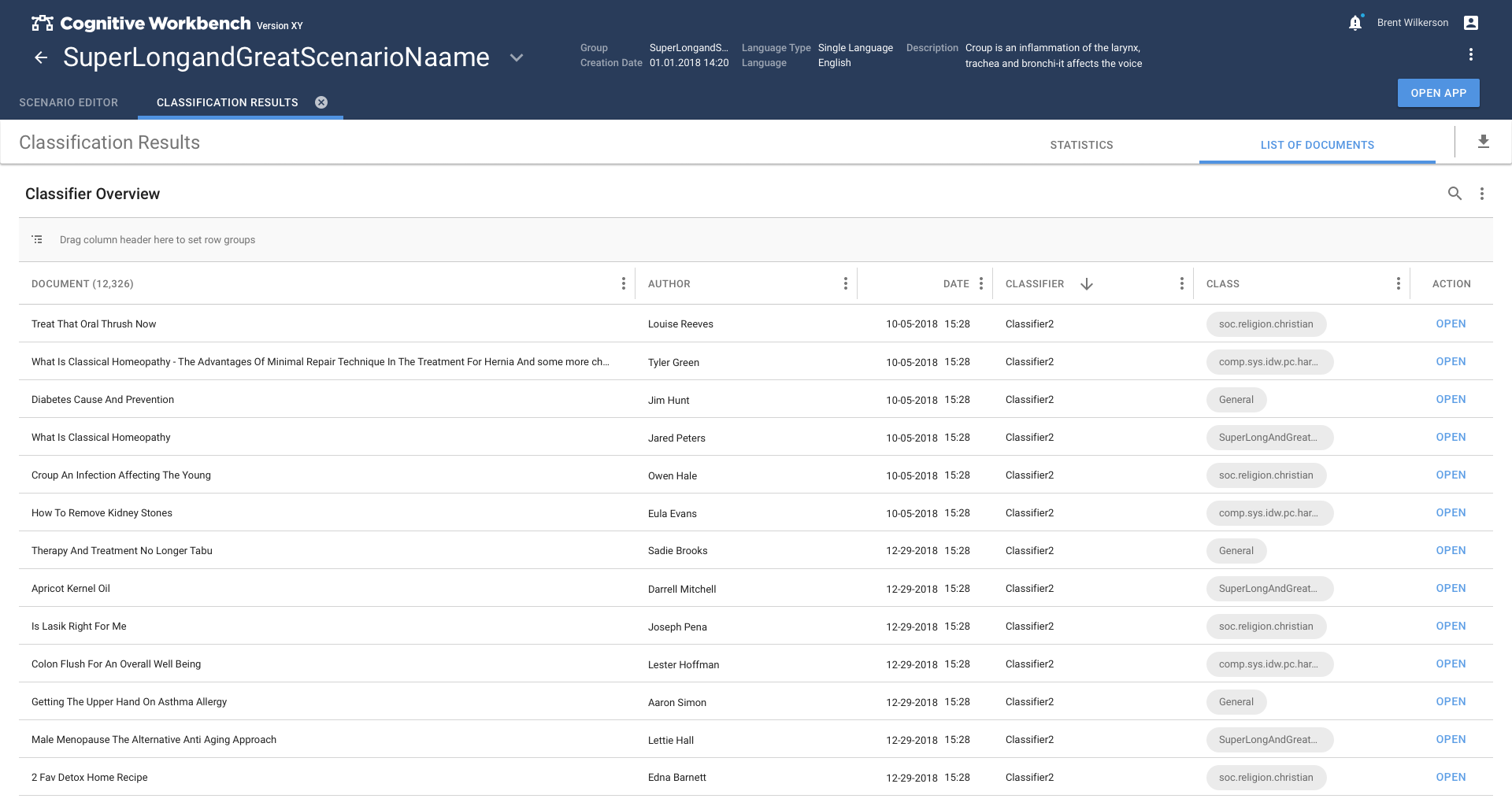
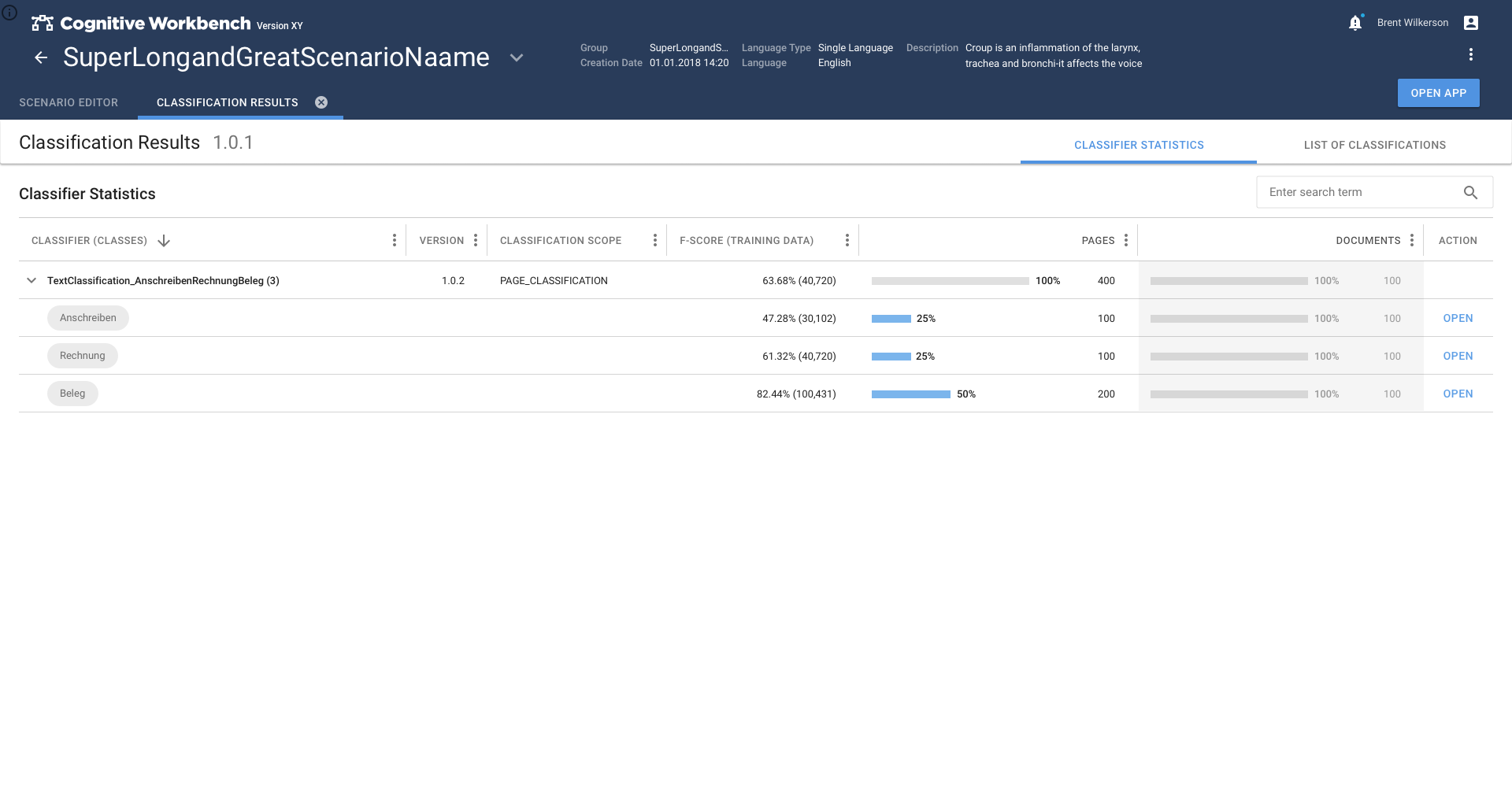
Text Classification was a very new field and we decided to cover this topic in two steps.
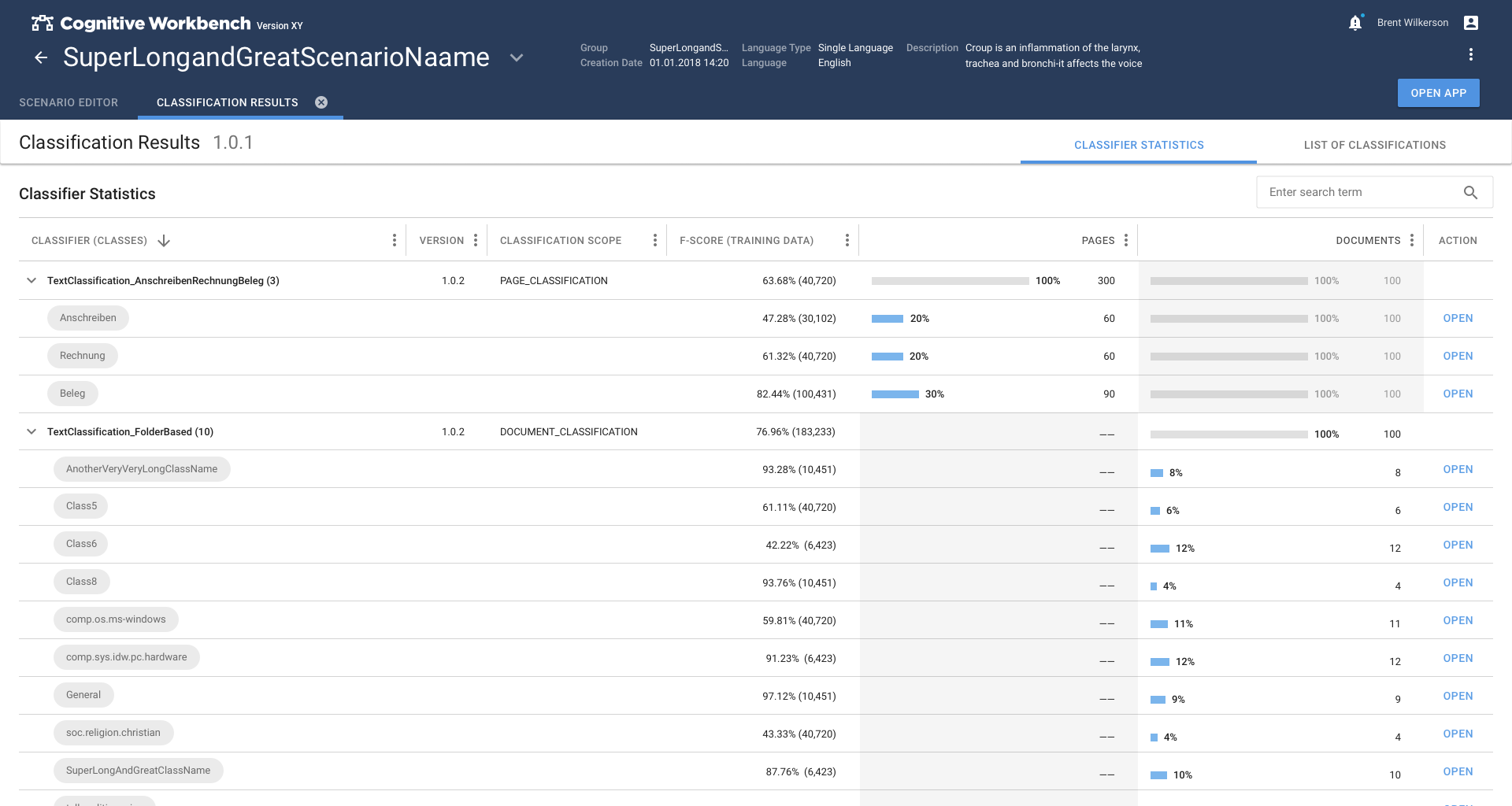
In the first phase, we explored the topic of text classification and estimated what is necessary to achieve good results. A simplified model based on folder-based learning was created. This allows the user to use information patterns in folders to teach the system what patterns look like.
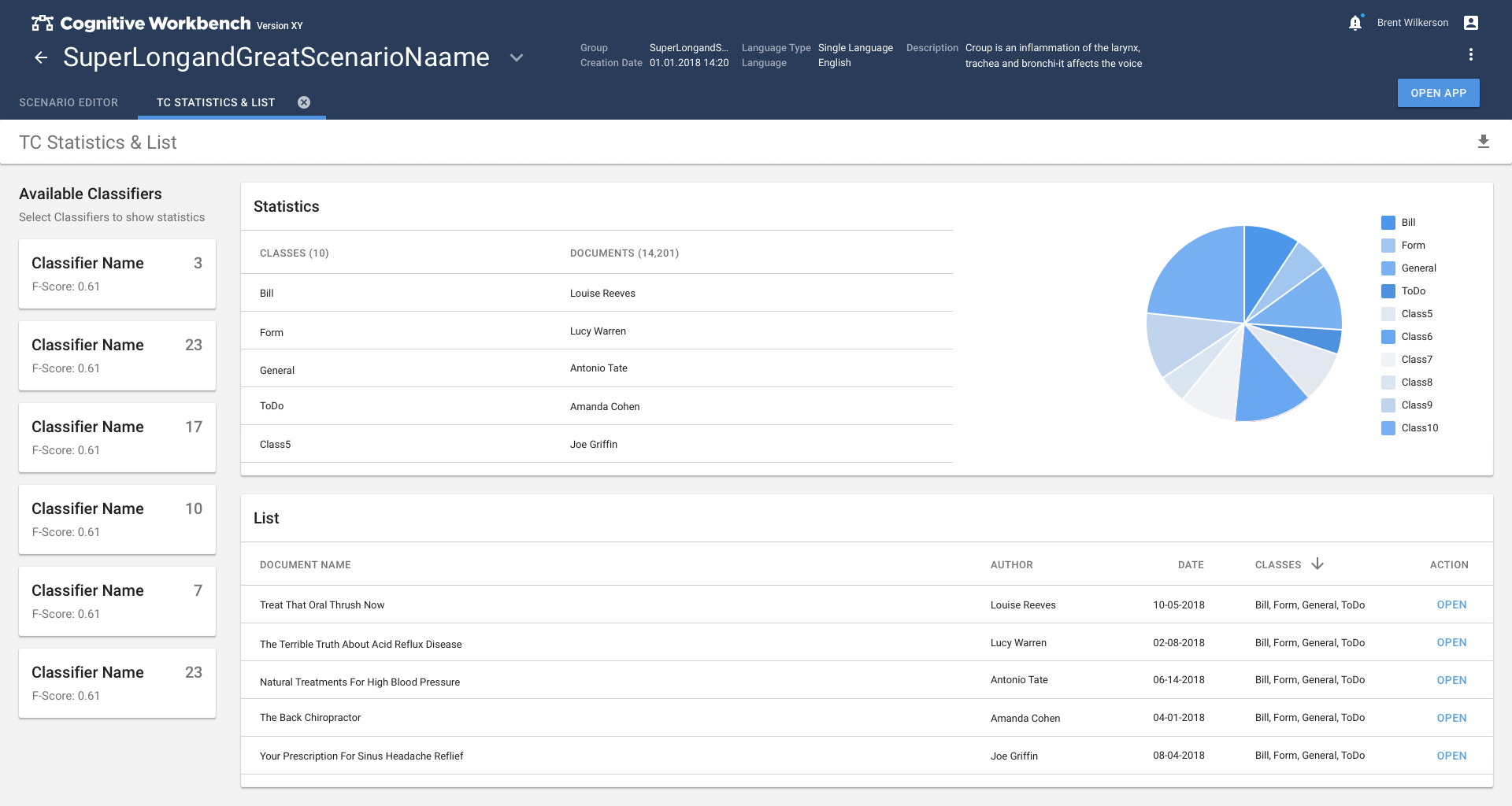
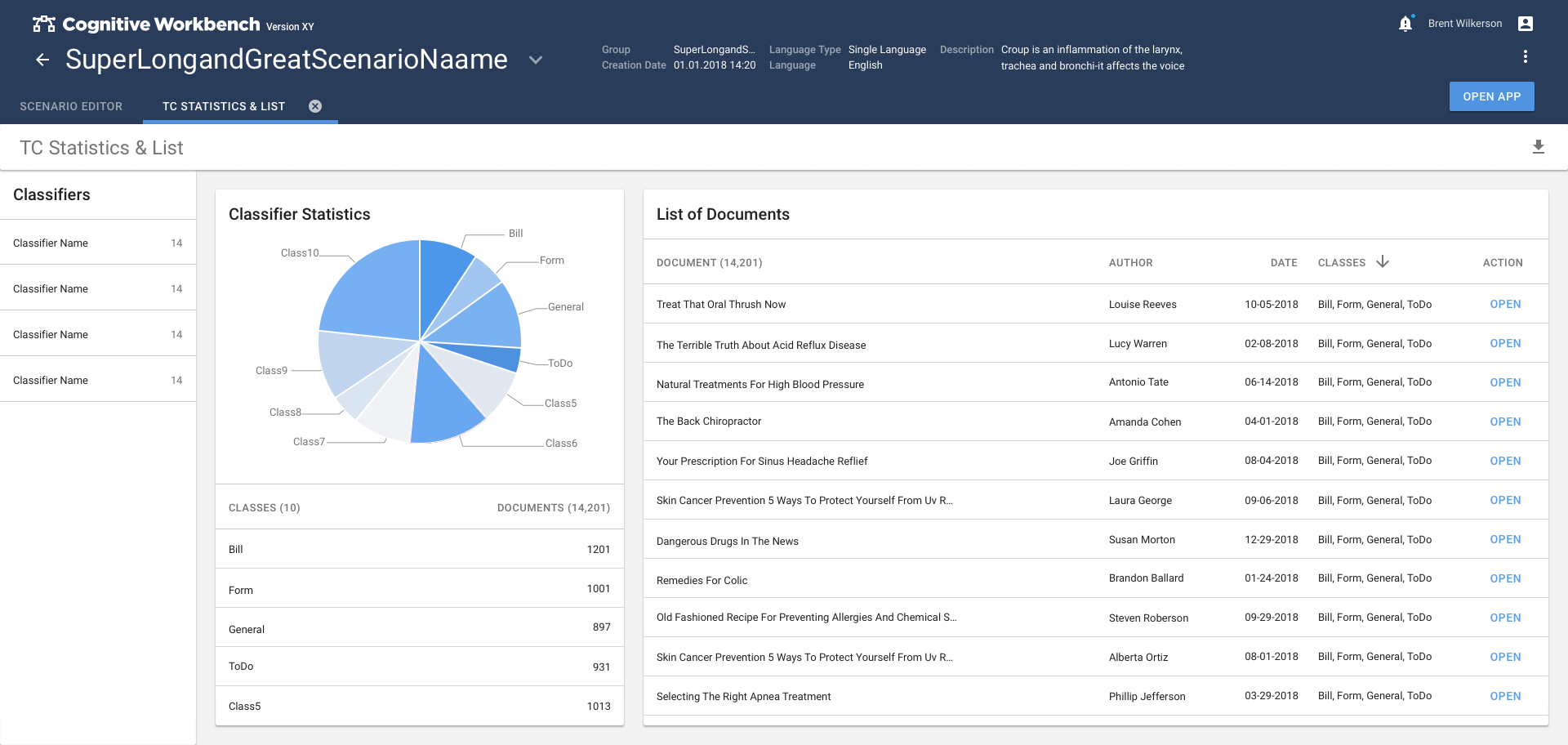
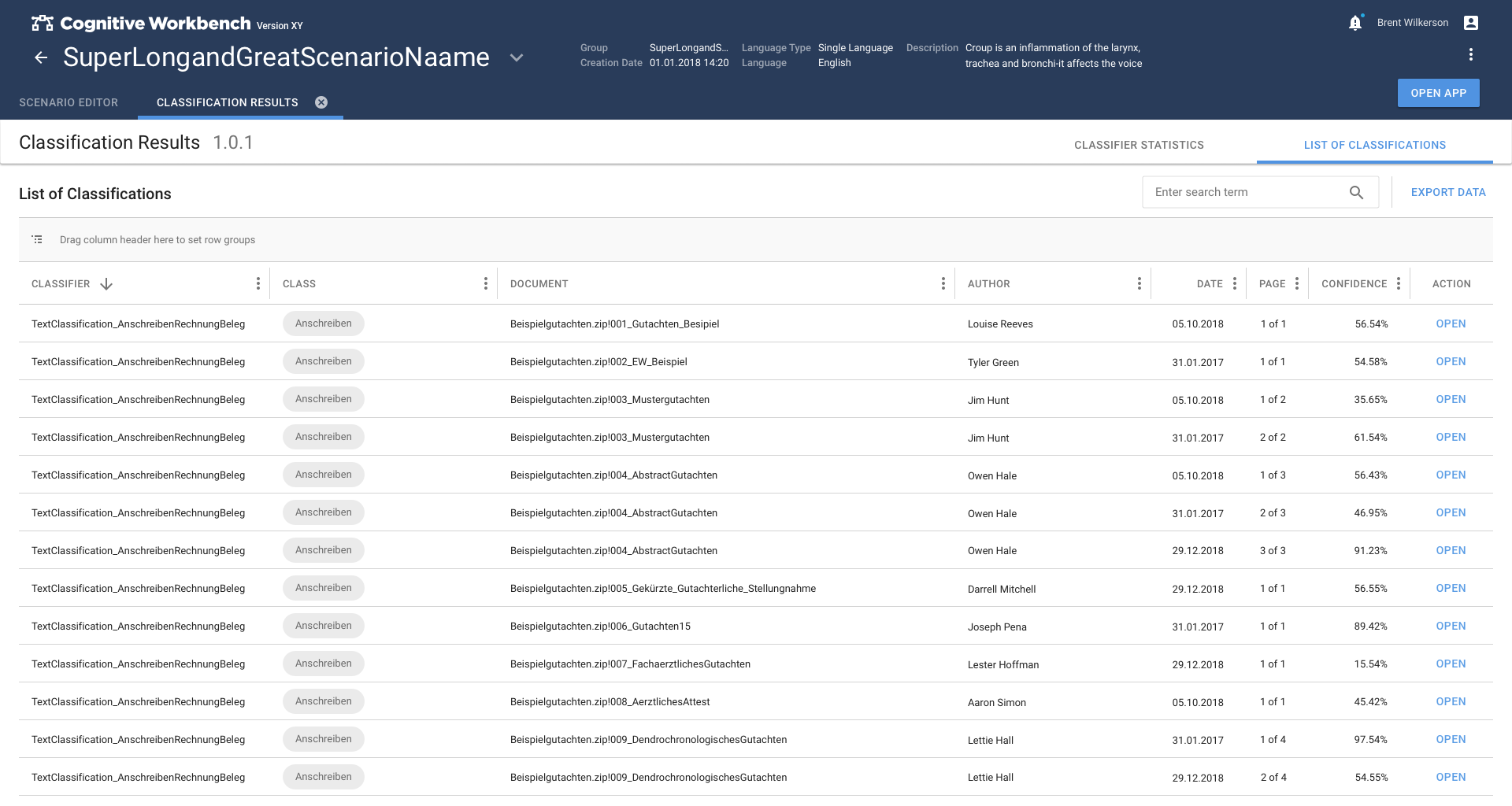
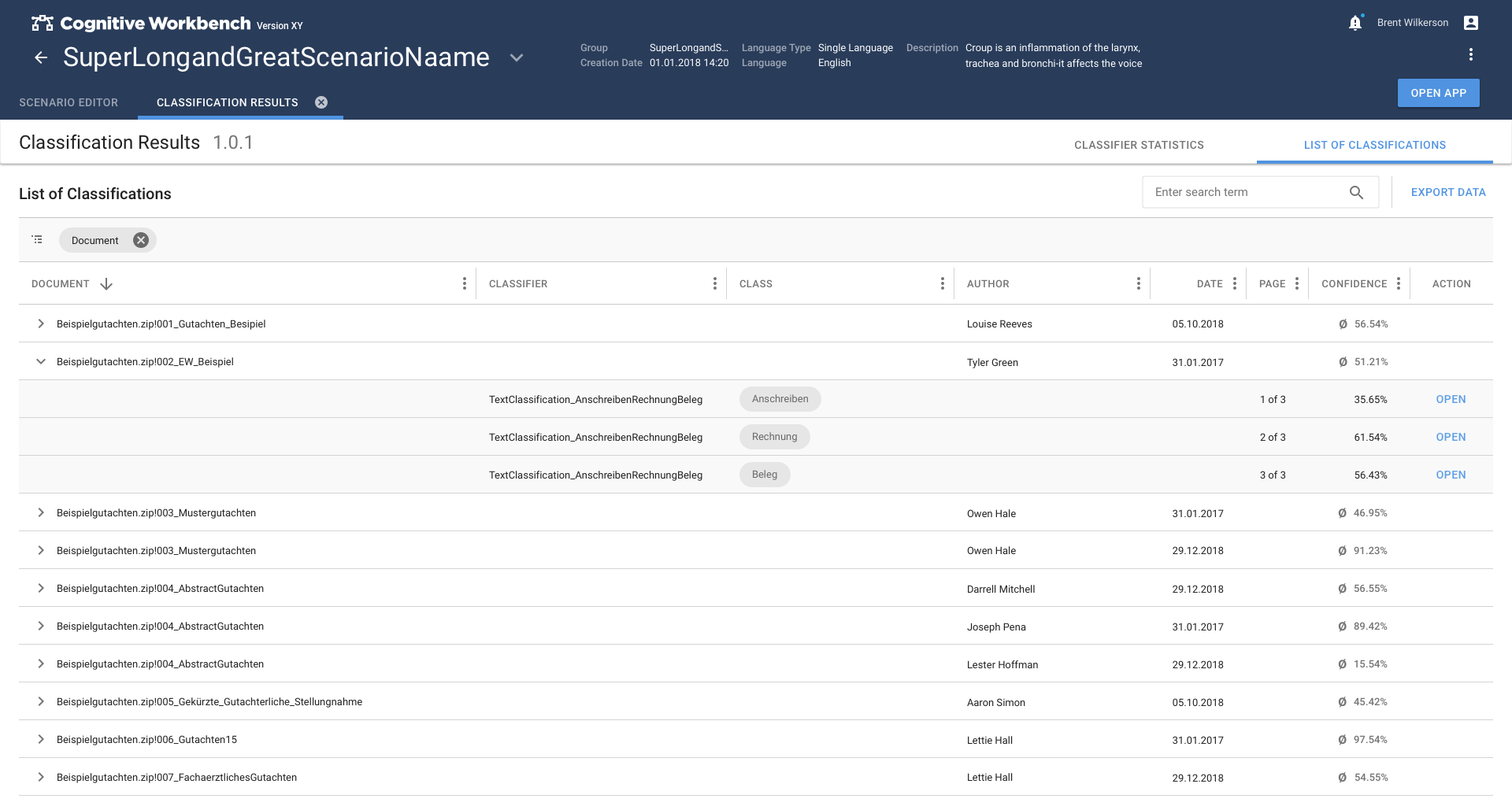
In the second phase, the method switched to the more promising method of classifying text passages by extracting information from the text. This caused so much refinement that the Text Classification app had to become the main task of the second phase.